For posts on psych-networks, I usually want to write about a topic for a few months, don’t find the time, and then a new paper comes along that prompts me to write up what I had in mind. For instance:
- A paper by Madhoo & Levin 2016 prompted me to write a tutorial on community detection
- A paper by Terluin et al. 2016 led to a blog post on differential variability
- A paper by Afzali et al. 2017 prompted me to write a tutorial on network stability
- A paper by Guloksuz et al. 2017 led me to write a piece on challenges of the network approach
- And a paper by Forbes et al. 2017 led to another blog post on stability
I wanted to write about centrality inference for a while, and a new paper published in Molecular Psychiatry, one of the leading journals in psychiatry in terms of impact factor and visibility, convinced me I should write this up. The paper is entitled “The symptom network structure of depressive symptoms in late-life: Results from a European population study”, by Murri and colleagues. This paper is written up in a similar way to many other papers, and I really don’t mean to single out this specific paper or the specific authors here. It just comes at a time where I don’t want to prepare my course or review the paper for Abnormal … so here we go.
Centrality
After estimating network structures, e.g. among symptoms, in between-subjects (cross-sectional) or within-subjects (time-series) data1, researchers often calculate centrality estimates. This provides information about the inter-connectedness of a variable. There are different ways to do that, and many different centrality measures exist.
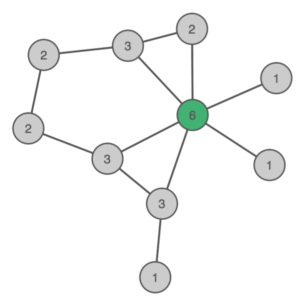
For instance, this R syntax creates a small network, and shows that the green node has a centrality of 6 because it is connected to 6 other variables:
library("qgraph")
AM <- matrix(0,10,10)
AM[1,2] <- AM[2,1] <- AM[2,3] <- AM[3,2] <- AM[2,4] <- AM[4,2] <- AM[3,4] <- AM[4,3] <- AM[3,6] <- AM[6,3] <- AM[3,8] <- AM[8,3] <- AM[3,9] <- AM[9,3] <- AM[3,10] <- AM[10,3] <- AM[4,7] <- AM[7,4] <- AM[5,7] <- AM[7,5] <- AM[5,10] <- AM[10,5] <- AM[9,10] <- AM[10,9] <- 1
gr <- list(c(1,2,4:10), 3)
names <- c("1","3","6","3","2","1","2","1","2","3")
N <- qgraph(AM, groups = gr, color=c('#cccccc', '#3CB371'), labels=names,
border.width=3,edge.width=2, vsize=9,
border.color='#555555', edge.color="#555555", label.color="#555555") |
In the abstract of their paper, Murri et al. conclude, after estimating a network structure in cross-sectional data:
Death wishes, depressed mood, loss of interest, and pessimism had the highest values of centrality. Insomnia, fatigue and appetite changes had lower centrality values […]. In conclusion, death wishes, depressed mood, loss of interest, and pessimism constitute the “backbone” that sustains depressive symptoms in late-life. Symptoms central to the network of depressive symptoms may be used as targets for novel, focused interventions and in studies investigating neurobiological processes central to late-life depression.
I am not sure this necessarily follows, and I will explain below why.
Problematic inferences
Researchers often estimate centrality values after the network structures are estimated, and then use these to draw substantive inferences. One common inference in cross-sectional data is that central symptoms are the most important symptoms, another that we should intervene on central symptoms. Murri et al. above describe that central symptoms “sustain” depression, which has a clear temporal component to it.
There are number statistical and substantive concerns you should keep in mind here. And just to clarify this again, this is not an exercise in finger-pointing. While I have always tried to be careful, and while my colleagues will tell you how careful I try to be when it comes to causal language (thanks in large part to my education as a postdoc in the lab of Francis Tuerlinckx), I am sure a few sentences have slipped through my fingers in papers I am co-author on. In my own work, the strongest statement I could find is in my first network paper, where we found loneliness to play a crucial role in bereavement, in longitudinal data. In the abstract, we concluded that “future studies should examine interventions that directly target such symptoms”. In the discussion, we wrote that “that intervention programs should directly target loneliness”. This is supported by and embedded in the clinical literature on the relation between loneliness and bereavement, but writing this paper today I would clarify that this conclusion does not follow from the network model alone.
So what are the main concerns and pitfalls when interpreting centrality values?
Statistical concerns
For my very first paper published in 2014, I analyzed the relations between 14 specific depression symptoms and impairment. It turned out that some symptoms explained a lot more variance than other symptoms. One of the reviewers raised the concern of differential variability, which I have not forgotten since. Differential variability means that items differ in their variability (standard deviation and variance), and items with little to no variability cannot relate to other variables. Since centrality is a function of relations among items, such floor or ceiling effects that can stem from differential variability will affect centrality estimates. Terluin et al. 2016 wrote a paper specifically about this for network models, which I discuss in more detail elsewhere. This means that when you estimate centrality, you should consider checking means and variances of items, and try to understand how these values determine network structures and centrality estimates. In other words, what happens if you correlate centrality values and standard deviations of your items … and they result in a correlation of 0.5? It’s worth thinking about this.
Another issue is reliable estimation: Are you sure the most central symptom in your network is actually meaningfully more central than the other symptoms? This is similar to other statistics, where the mean height of 177cm in a group of men vs 171 cm in a group of women does not tell you if there is a meaningful (or statistically significant) difference between the height of men and women — unless you know the sample size and distributions. You can test this statistically, and probably want to do that before drawing inferences. We describe here how to do that in detail, via the centrality difference test.
What if 3 nodes in your network actually measure the same latent variable, such as the CES-D scale that captures sad mood, feeling blue, and feeling depressed? Your network will feature strong edges between these nodes, and their centrality will be very high, but intervening on either to decrease the others would not be a real “network intervention” because all you do is reducing sadness by intervening on sadness. That may be interesting all by itself, but the edges between these 3 items are not legitimate putative causal relations: They are simply shared variances due to measuring the same thing multiple times, as we highlight (along with a potential solution to this) in our challenges paper published in Perspectives on Psychological Science.
There is also the danger of conditioning on colliders or other estimation problems. Conditioning on colliders, for instance, will induce artificial edges in your network that are not part of the true model. In other words, be careful not to confuse an estimated parameter (like an edge weight) for the truth … obviously, this applies to all models, and not only network models.
Finally, there is the issue of mixing levels. Network models in cross-sectional data are estimated on between-subjects data, and as has been highlighted in recent work, it does not automatically follow that such results lead to proper conclusions regarding the within-subjects level. I am not saying it never follows, and I think these levels might align quite often, but it is an empirical question we have not yet answered. Here a fairly strongly worded recent investigation by Fisher et al. published in PNAS showing that there are important differences between these levels; Simpson’s paradox is also highly relevant on this context.
Substantive concerns
Now let’s assume our network is estimated without any problems or bias, and concentration problems is the most central depression symptom in the network structure of symptoms based on cross-sectional data. Can we conclude that it is the “most important” problem, and that we should focus our interventions on concentration problems?
As we wrote up in the discussion section of a recent paper we published in Clinical Psychology Science, this conclusion does not necessarily follow, for various reasons.
It is important to highlight that centrality does not automatically translate to clinical relevance and that highly central symptoms are not automatically viable intervention targets. Suppose a symptom is central because it is the causal endpoint for many pathways in the data: Intervening on such a product of a causal chain would not lead to any changes in the system.
In other words, the endpoint of a causal chain would end up being a highly central symptom in your network structure if there are many problems that lead to this specific symptom. Given the cross-sectional nature of your data, you cannot find evidence for this temporal relationship, and will, in this case, draw wrong causal inferences that does not follow from the results. So I urge caution with these and similar interpretations.
Another possibility is that undirected edges imply feedback loops (i.e., A—B comes from A↔B), in which case a highly central symptom such as insomnia would feature many of these loops. This would make it an intervention target that would have a strong effect on the network if it succeeded — but an intervention with a low success probability, because feedback loops that lead back into insomnia would turn the symptom “on” again after we switch it “off” in therapy.
Put differently, it is an important and non-trivial question if it might not be worthwhile to intervene on peripheral (non central) symptoms, because the probability of switching them permanently is higher: Few other symptoms will keep them in their original state. If sleep problems leads to 5 other problems, but is at the same time the consequence of 5 problems, it will be nearly impossible to simply target insomnia via interventions because you don’t target the causes of insomnia.
A third example is that a symptom with the lowest centrality, unconnected to most other symptoms, might still be one of the most important clinical features. No clinician would disregard suicidal ideation or paranoid delusions as unimportant just because they have low centrality values in a network. Another possibility is that a symptom is indeed highly central and causally affects many other nodes in the network but might be very difficult to target in interventions. As discussed by Robinaugh, Millner, and McNally (2016), “Nodes may vary in the extent to which they are amenable to change” (p. 755).
I believe these are significant challenges to common centrality interpretations. We conclude in the paper by stating:
In sum, centrality is a metric that needs to be interpreted with great care and in the context of what we know about the sample, the network characteristics, and its elements. If we had to put our money on selecting a clinical feature as an intervention target in the absence of all other clinical information, however, choosing the most central node might be a viable heuristic.
There is other critical work on centrality on the way. One paper that is accepted in the Journal of Consulting and Clinical Psychology, by Rodebaugh and colleagues, features a detailed empirical investigation of centrality in both cross-sectional and time-series data. You can find the preprint here. The most relevant parts of the abstract read:
We first estimated a state-of-the-art regularized partial correlation network based on participants with social anxiety disorder (N = 910) to determine which symptoms were more central. Next, we tested whether change in these central symptoms were indeed more related to overall symptom change in a separate dataset of participants with social anxiety disorder who underwent a variety of treatments (N = 244). […] Centrality indices successfully predicted how strongly changes in items correlated with change in the remainder of the items. Findings were limited to the measure used in the network and did not generalize to three other measures related to social anxiety severity. In contrast, infrequency of endorsement2 showed associations across all measures. […] The transfer of recently published results from cross-sectional network analyses to treatment data is unlikely to be straightforward.
Conclusions
The whole idea of network theory is that things are complicated. We should draw inferences proportional to this level of complexity, and be careful of over-interpreting our data. Obviously, this is just as important for time-series analyses, where we have time as an additional (and very important) dimension, but that only buys us Granger-causality, and only helps with a few of the issues described above.
A crucial step forward is to actually test interventions in patients based on centrality (and other) estimations, and I am excited to see such projects putting network theory to the test — and provides a fantastic opportunity for falsification of network theory we should all embrace.
EDIT 11-29-2018:
There are two new preprints discussing centrality inferences critically, which you can find here (Dablander & Hinne, 2018) and here (Bringmann et al., 2018).
Pingback: (Mis)interpreting Networks: An Abbreviated Tutorial on Visualizations | Psych Networks
This post is super interesting and sort of turned my project upside down. Are you as concerned with centrality measures in temporal networks? Because (I think that) many people would say that causality is clearer when you use temporal networks, but I’m skeptical about that. Also, what do you think about using centrality measures, not as intervention targets but, as predictors of future psychopathology?
Temporal data provide you with granger-causal inferences, but not causal inferences. And I find centrality in temporal data more interesting, but it does not get around certain issues such as including several nodes that measure the same construct, which biases centrality estimates.
Pingback: Tutorial: how to review psychopathology network papers | Psych Networks
Pingback: Looking back at 2018 - Eiko Fried
Pingback: Summary of my academic 2018 - Eiko Fried